

📊 Data Job Signals #01
Relatório de Vagas em Ciência de Dados no Brasil — Junho de 2025 Produto do projeto Job Data Insight | SDL
Jhonathan Domingues
🧭 Introdução: Por que analisar as vagas?
O mercado de dados no Brasil vem mudando rapidamente — mas o que realmente está sendo pedido nas vagas? Quais são os padrões, mudanças e sinais que indicam ajustes nos critérios de contratação?
Este relatório é uma análise exploratória inicial, feita a partir de 75 vagas para Cientista de Dados publicadas no LinkedIn Brasil entre 01 e 14 de junho de 2025.
O objetivo aqui não é fornecer respostas definitivas — mas sim levantar sinais, fomentar discussões e gerar inteligência prática sobre as exigências do mercado.
🔍 Objetivo principal
Investigar a coerência entre o que as empresas declaram e o que realmente exigem nas descrições de vaga — em termos técnicos, comportamentais e de senioridade.
🔧 Como os dados foram obtidos?
A metodologia do relatório busca estruturar de forma sistêmica os dados não padronizados presentes nas descrições de vagas:
Coleta manual dos links das vagas
Captura do HTML completo de cada descrição
Processamento automatizado via agente GPT, responsável por extrair:
Hard skills
Soft skills
Idiomas
Benefícios
Sinais de senioridade
Cada vaga foi analisada segundo:
Nível de experiência declarado
Nível estimado com base nas exigências técnicas
Grau de coerência entre ambos
As empresas foram anonimizadas com codinomes como Fintech_SP_01, para garantir uma análise ética e livre de conflitos.
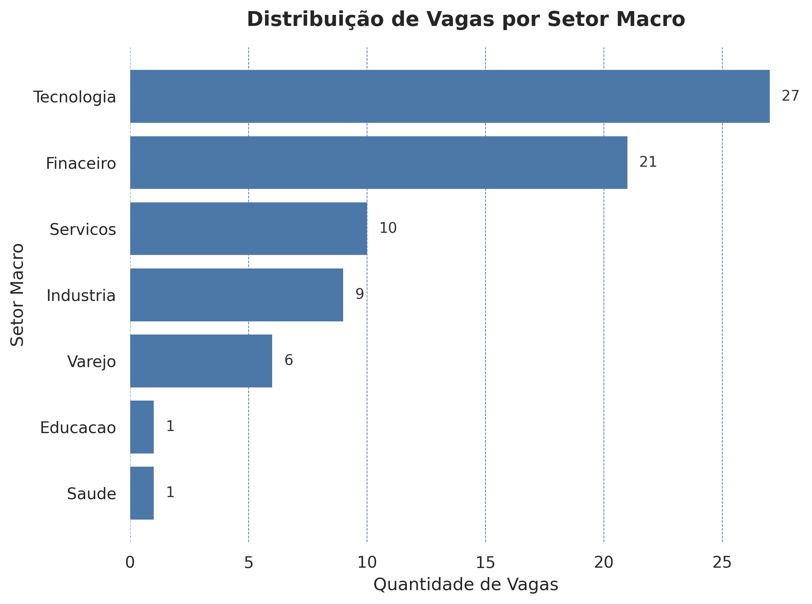
🏷️ Setores e Distribuição das Vagas
As vagas foram categorizadas manualmente por setor de atuação. A segmentação mostra um padrão claro:
📌 Tecnologia, Finanças e Serviços concentram a maior parte das oportunidades.
Esses setores continuam sendo os motores principais da demanda por profissionais em dados no país.
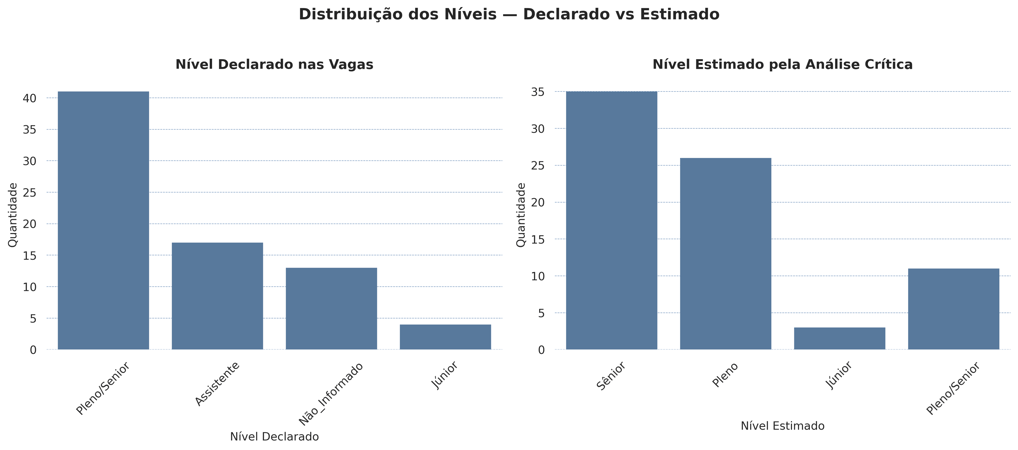
🎯 Senioridade Declarada vs Realidade Técnica
Um dos pontos centrais da análise foi comparar o nível declarado na vaga (Júnior, Pleno, Sênior) com o nível realmente exigido pelas competências técnicas e comportamentais descritas.
📌 Resultado principal:
🟡 61% das vagas estavam em subdeclaração — ou seja, pedem mais do que comunicam.
Outros achados:
Vagas Júnior e Assistente são raríssimas
Exigências robustas aparecem mesmo em vagas rotuladas como Pleno
O título da vaga muitas vezes não reflete o nível real esperado
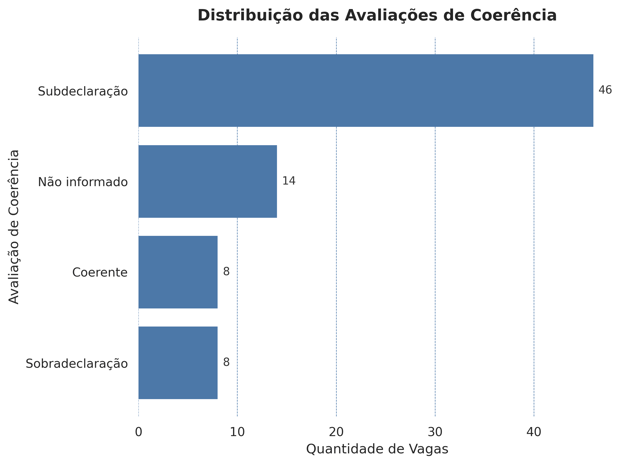
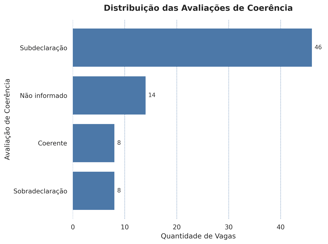
🧮 Avaliação de Coerência
📌 Resultado:
Subdeclaração lidera com 61%
Apenas 11% das vagas foram plenamente coerentes
Cada vaga foi classificada em uma das quatro categorias abaixo:
✔️ Coerente – o que é pedido bate com o título
⚠️ Subdeclaração – pede mais do que comunica
❗ Sobradeclaração – comunica mais do que pede
❔ Não informado – não menciona explicitamente o nível

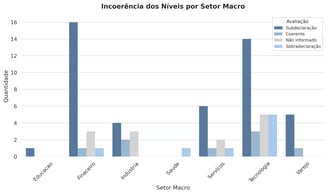
🔍 Onde estão os desalinhamentos?
A incoerência aparece em todos os setores e níveis analisados.

Tecnologia e Finanças lideram tanto em volume de vagas quanto em desalinhamento
O rótulo “Pleno” parece ser usado de forma genérica
Vagas rotuladas como “Assistente” frequentemente apresentam exigências técnicas equivalentes a Sênior
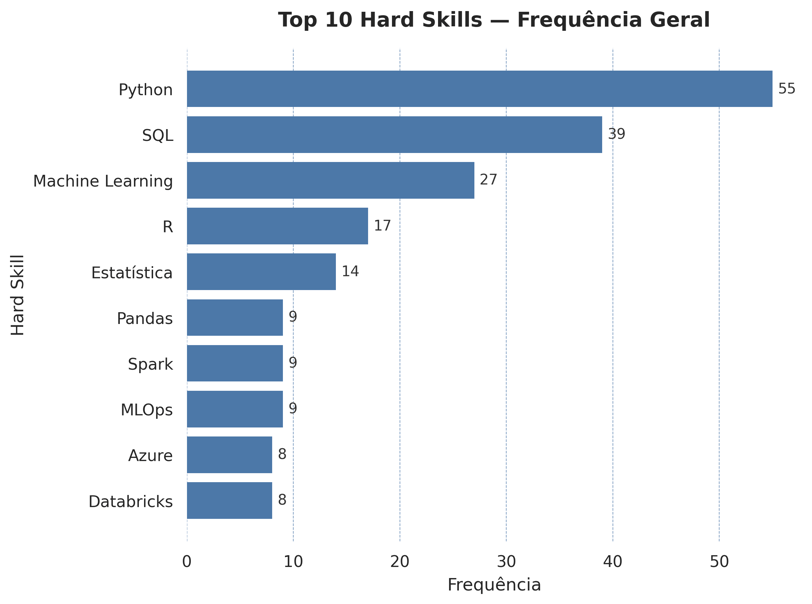
Na análise das hard skills, o padrão técnico é forte e repetitivo:
Python e SQL lideram com folga
Machine Learning, Estatística e Pandas formam a base comum
Spark, Azure, Databricks e práticas de MLOps aparecem mesmo em vagas que não pedem senioridade explícita
🧱 O que as empresas estão pedindo, afinal?
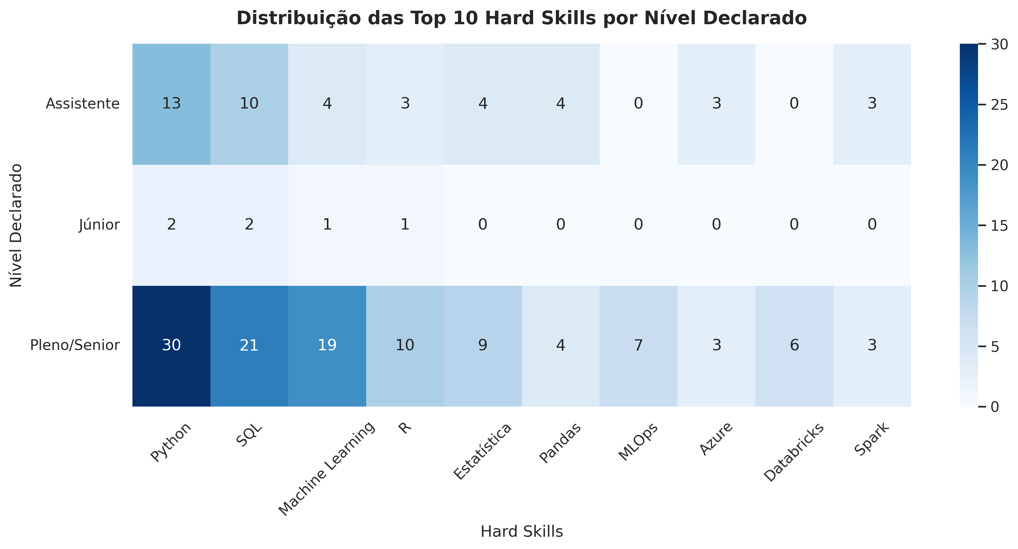
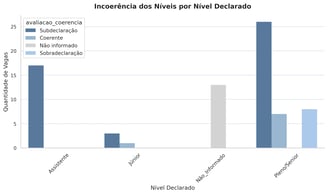
🔥 Heatmap – Hard Skills por Nível Declarado
O heatmap revela:
Vagas rotuladas como Assistente incluem stacks complexas como Spark e Deep Learning
Vagas Júnior trazem cargas técnicas que beiram o nível Pleno
O nível Sênior está alinhado ao esperado — mas os níveis abaixo estão desajustados
📌 Discussões e Hipóteses
O desalinhamento entre rótulo e exigência não é um acaso. Algumas hipóteses:
🔍 Pressão seletiva por perfis experientes
🧱 Estruturação fraca nos processos de recrutamento
🤖 Automatização de descrições baseada em padrões antigos
📉 Redefinição silenciosa dos critérios de senioridade
💬 Falta de alinhamento entre áreas técnicas e RH
Esses fatores ajudam a explicar por que tantas vagas demandam muito, comunicam mal e ignoram os perfis de entrada.
📜 Conclusão Final
Este relatório foi concebido como um primeiro passo para mapear o terreno e identificar pontos de atenção que influenciam a evolução da área de dados no Brasil.
Não é um retrato definitivo.
Mas revela padrões consistentes que merecem discussão aberta dentro da comunidade.
📌 Principais achados:
O nível Pleno domina — mas muitas vezes esconde demandas de Sênior
Perfis de entrada têm pouco espaço
A comunicação de senioridade nas vagas é inconsistente
Existe uma pressão técnica crescente no mercado
🔗 Notebook e Dados no GitHub
Inclui os dados estruturados, gráficos, análises e scripts utilizados neste relatório.:
→ 🔗 Acessar notebook no GitHub
🛑 Disclaimer
Este relatório é uma análise independente, sem vínculos institucionais ou comerciais.
Todos os dados utilizados são públicos, anonimizados e tratados com responsabilidade.
O objetivo é gerar inteligência aplicada sobre o mercado de dados no Brasil e fomentar reflexões construtivas.
Small Data Lab
Ciência de Dados em Movimento
© 2025 Small Data Lab - Todos os direitos reservados
Contato: contato@smalldatalab.com.br